IO 专题
在Monad专题中,我们已经介绍了一些有关IO作为monad的性质和用法,本章我们将着重讲解使用IO monad进行系统编程。
纯度与副作用
纯代码(purity) 和无 副作用(side effect) 是Haskell最基本的特性。对于一个纯函数,其结果完全由参数决定,一旦参数确定了,那么结果是唯一确定的,且不受时间或外界环境的影响。纯函数是无副作用的,与之相对的,不纯函数往往会伴随除了计算之外的行为,如程序的输入和输出等。Haskell作为程序语言,需要与现实世界产生作用,这将不可避免地带来副作用。
IO monad
Haskell将IO操作装入monad中,得到IO monad。一方面,我们可以在IO monad中执行副作用,而不会将影响传到其他纯代码中;另一方面,我们仍然可以在IO操作中进行计算,并传递计算结果。
对于一个类型为IO a的值,它表示该值进行若干的IO操作,并最终得到一个类型为a的计算结果,这个计算结果存储在monad内部,可以通过特定的方式进行传递。
回顾单子类型类的定义:
class Applicative m => Monad m where
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
return :: a -> m a
fail :: String -> m a
{-# MINIMAL (>>=) #-}
Monad类型类的最小实现为(>>=),它接受一个容器m a,以及一个类型为a -> m b的函数,并将第二个函数依次应用于第一个容器中的元素,最后生成新的容器。return函数将一个数值a映射为包含该元素的容器,对应了Applicative中的pure函数;(>>)类似(>>=),区别是(>>)并没有将第一个参数传入第二个参数中;最后fail用于计算错误时进行报错。
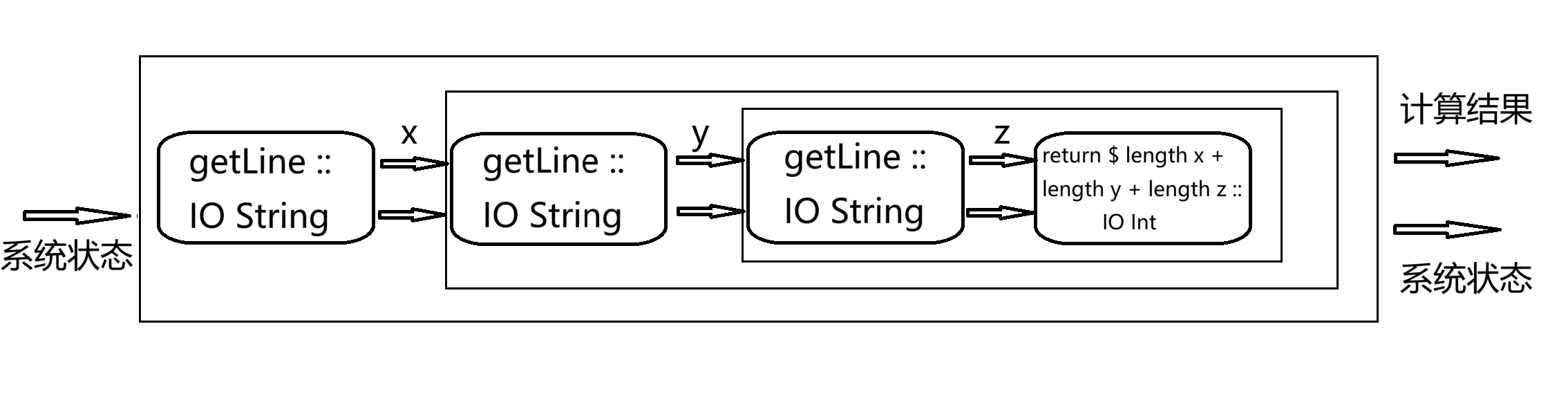
使用>>=可以将IO操作串联起来,例如计算三个输入的字符串的长度和:
-- code'3.hs
threeStrLn :: IO Int
threeStrLn =
getLine >>=
(\x -> getLine >>=
(\y -> getLine >>= (
\z -> return $ length x + length y + length z)
))
三个getLine分别从键盘读取一行字符串,并分别传递给x,y和z,最后计算三个字符串的长度并封装到IO monad中。
当然上述代码也可以使用do 语句改写:
-- code'3.hs
threeStrLn' :: IO Int
threeStrLn' = do
x <- getLine
y <- getLine
z <- getLine
return $ length x + length y + length z
两者是完全等效的。
可变数据 Data.IORef
在纯代码中,“变量”是不可变的,即一旦我们为变量分配了值后,就不能修改这个值。Haskell 提供了一个在IO monad中修改变量内存的模块Data.IORef,该模块提供了IORef容器以及相关的功能函数,使我们能够直接修改容器中的变量。
| 函数名称 | 类型签名 | 功能 |
|---|---|---|
| newIORef | a -> IO (IORef a) | 新建IORef |
| readIORef | IORef a -> IO a | 读取IORef中的值 |
| writeIORef | IORef a -> a -> IO () | 向IORef写入值 |
| modifyIORef | IORef a -> (a -> a) -> IO () | 修改IORef中的值 |
| modifyIORef' | IORef a -> (a -> a) -> IO () | 严格(非惰性)修改IORef中的值 |
| atomicModifyIORef | IORef a -> (a -> (a, b)) -> IO b | 原子地修改IORef中的值 |
| atuomicModifyIORef' | IORef a -> (a -> (a,b)) -> IO b | 原子地严格(非惰性)修改IORef中的值 |
| atomicWriteIORef | IORef a -> a -> IO () | 原子地向IORef写入值 |
| mkWeakIORef | IORef a -> IO () -> IO (Weak (IORef a)) | 创建弱指针对象 |
上述函数中,前四个比较基础,下面给出使用示例:
-- code'3.hs
iorefDemo :: IO ()
iorefDemo = do
x <- getLine
aref <- newIORef x
val <- readIORef aref
print val
y <- getLine
writeIORef aref y
val <- readIORef aref
print val
modifyIORef aref ("modified :" ++ )
val <- readIORef aref
print val
该示例首先读取一行字符串x,使用newIORef创建一个IORef容器aref,并将x赋值,赋值后使用readIORef将值读入val并输出;接着读取新的一行字符串y,并通过writeIORef将其写入aref中,写入后将值读入val并输出;最后,用modifyIORef对aref内的值进行修改,在其字符串前添加"modified :",重新读取值到val并输出。
Prelude> :load code'3.hs
[1 of 1] Compiling Main ( code'3.hs, interpreted )
Ok, one module loaded.
Prelude> iorefDemo
hello
"hello"
hello haskell
"hello haskell"
"modified :hello haskell"
除了基础的四个函数操作,atomicModifyIORef以原子方式进行修改,该函数对于在多线程中使用IORef非常有用,当只有一个IORef时,atomicModifyIORef函数,可以阻止多个线程因访问其而可能产生的竞争状态;atomicWriteIORef以原子方式进行写入;最后mkWeakIORef创建一个指向IORef的弱指针。
补充:大多数现代的CPU架构都有一个内存模型,这个模型会允许线程对读取操作和写入进行重排,以使读取早于写入,例如x86/64架构,而原子方式则会强制一个内存屏障以阻止原子块中的读写操作的重排
提示: 有关严格求值版本的细节可参阅Data.IORef,有关弱指针的细节可参阅System.Mem.Weak
数据读写
对于数据进行读写实际上是对于 句柄(handle) 的操作,无论对于文件或者数据流的读写,均基于句柄进行操作。句柄在Haskell中的类型为Handle,我们常用的标准输入输出stdin和stdout的类型均为Handle。数据读写相关的定义位于Sytem.IO。
接下来我们依托文件系统讲解有关读写的相关定义和用法。
读写模式
data IOMode = ReadMode | WriteMode | AppendMode | ReadWriteMode
系统为读写模式定义了四种模式,其中ReadMode为只读;WriteMode为只写,写入内容会覆盖已经存在的内容,如果不存在则先创建;AppendMode为只添加,写入内容会添加到末尾,如果不存在则先创建;ReadWriteMode为读写,既可以读也可以写,当文件不存在时自动创建。
基于上面的模式,Haskell提供了若干打开文件的函数:
readFile :: FilePath -> IO String: 读取模式打开文件writeFile :: FilePath -> String -> IO (): 写模式打开文件appendFile :: FilePath -> String -> IO (): 添加模式打开文件openFile :: FilePath -> IOMode -> IO Handle: (以某种模式)打开文件
上述函数中前三个函数将句柄封装起来,方便我们根据需要直接进行相关文件操作;而第四个函数openFile允许我们更自由操作句柄,当我们完成对句柄的操作后,需要对句柄进行关闭hClose。
句柄读操作
Haskell提供了一些句柄读操作,这里给出一些常见的函数。
hGetChar :: Handle -> IO Char: 读取一个字符,访问位置向后移动一位(可能会导致isEOFError,位于System.IO.Error)hGetLine :: Handle -> IO String: 读取一行字符,访问位置向后移动一行(同样可能导致isEOFError)hLookAhead :: Handle -> IO Char: 向后读取一个字符,但访问位置不移动(同样可能导致isEOFError)hGetContents :: Handle -> IO String: 读取全部内容,并自动关闭句柄
补充:
hGetContents作为惰性求值的函数,因此当我们执行这个函数时并没有读取任何字符串,这允许其读取很大的文件而不必担心内存分配问题似乎
hGetContents的惰性读取字符串和关闭句柄之间是矛盾的,实际上,这个关闭状态是一种中间态,hGetContents仍然可以从中读取内容,虽然使用hIsClosed函数查看到的状态是关闭的
hGetContents在句柄完全关闭的状态是无法进行读取的,因此当我们执行完hGetContents函数后,在使用hClose关闭句柄后尝试读取hGetContents得到的结果时,会产生异常因此,Haskell提供了一个严格求值版本的
hGetContents'
另外,针对标准输入,Haskell还提供了一些特例函数,这些函数可以认为是上述函数的部分应用函数。
getChar :: IO Char: 向标准输入读取一个字符,等同于hGetChar stdingetLine :: IO String: 向标准输入读取一行字符串,等同于hGetLine stdingetContents :: IO String: 读取所有标准输入,等同于hGetLine stdin,严格求值版本为getContents'
句柄写操作
除了读操作,Haskell还提供了一些写操作,下面给出一些常见的函数。
hPutChar :: Handle -> Char -> IO (): 向句柄中写入一个字符hPutStr :: Handle -> String -> IO (): 向句柄中写入一个字符串hPutStrLn :: Handle -> String -> IO (): 向句柄中写入一个字符串,并另起一行(添加一个换行符)hPrint :: Show a => Handle -> a -> IO (): 向句柄中写入一个满足Show约束的类型的值
特别地,针对标准输出,Haskell提供了一些特例函数。
putChar :: Char -> IO (): 向标准输出写入一个字符,等同于hPutChar stdoutputStr :: String -> IO (): 向标准输出写入一个字符串,等同于hPutStr stdoutputStrLn :: String -> IO (): 向标准输出写入一个字符串,并另起一行,等同于hPutStrLn stdoutprint :: Show a => a -> IO (): 对可展示的类型(受到Show约束)的值输出,等同于\t -> hPutStrLn stdout (show t)
句柄访问位置
当我们访问文件句柄时,会存在一个访问位置,从此位置可以进行读取或者写入操作。通过hTell :: Handle -> IO Integer函数可以获取当前句柄的绝对位置,即从初始位置到当前位置间隔的字节数目。特别地,hIsEOF :: Handle -> IO Bool函数用于判断是否到达了文件末尾。
我们还可以通过hSeek函数改变句柄访问位置,在介绍hSeek函数之前,我们首先了解句柄访问位置的移动参照。
data SeekMode = AbsoluteSeek | RelativeSeek | SeekFromEnd
其中AbsoluteSeek为绝对移动,即从初始位置到目标位置间隔的字节数;RelativeSeek为相对移动,即从当前位置移动的字节数,可以为负值(表示向前);SeekFromEnd从文件末尾向前移动一定的字节数。
hSeek函数的类型为Handle -> SeekMode -> Integer -> IO (),我们只需要提供句柄,移动参照模式以及一个偏移量即可改变句柄访问地位置。
下面提供一个综合的例子:
-- code'3.hs
fileDemo :: IO ()
fileDemo = do
file <- openFile "test.txt" ReadWriteMode
pos <- hTell file
print pos
hPutStr file "hello world"
pos <- hTell file
print pos
hSeek file AbsoluteSeek 6
c <- hLookAhead file
print c
pos <- hTell file
print pos
hPutStr file "new world"
hClose file
x <- readFile "test.txt"
print x
Prelude> fileDemo
0
11
'w'
6
首先,程序以读写模式打开test.txt文件(如果没有直接创建),此时访问位置为0,从此处进行写入"hello world",一共写入11个字符,因此访问位置变为11,接着移动到第六个字符的位置(访问得到此处字符为'w',并保持访问位置不变),从此处写入"new world"之后关闭文件。重新读取文件,得到内容为覆盖后的内容"hello new world"。
缓冲区模式
一般地,从数据流中进行读取或向其中写入数据要比处理这些内容的时间长,因此系统在内存中设置 缓冲区(buffer) ,用来临时处理读写的内容,只有当缓冲区装满后才会进行刷新(即将内容真正读写到数据流中)。
在Haskell中定义了三种不同的缓冲区模式:
data BufferMode = NoBuffer | LineBuffering | BlockBuffering (Maybe Int)
可以看到缓冲区分为三类,NoBuffer表示无缓冲模式,此时字符将被逐个处理;LineBuffering表示行缓冲模式,字符串以行单位被处理;BlockBuffering表示块缓冲模式,字符串被存储在指定字节长度的缓冲区中被操作,这是Haskell默认的缓冲模式(参数设置为Nothing)。我们可以通过hGetBuffering :: Handle -> IO BufferMode查看句柄的缓冲区模式。
另外,我们还可以使用hSetBuffering :: Handle -> BufferMode -> IO ()可以改变缓冲区的模式。下面的两个示例,通过更改缓冲区模式,在缓冲区未装满的情况下,使用hFlush :: Handle -> IO ()函数进行手动刷新,对比刷新前后的写入情况。
-- code'3.hs
setLineBufferingDemo :: IO ()
setLineBufferingDemo = do
file <- openFile "test.txt" WriteMode
hSetBuffering file LineBuffering
hPutStr file "abc"
getLine -- 暂停查看test.txt 内容
hFlush file
getLine -- 查看刷新后的test.txt 内容
hClose file
setBlockBufferingDemo :: IO ()
setBlockBufferingDemo = do
file <- openFile "test.txt" WriteMode
hSetBuffering file (BlockBuffering (Just 10))
hPutStr file "abc"
getLine -- 暂停查看test.txt 内容
hFlush file
getLine -- 查看刷新后的test.txt 内容
hClose file
以上两个示例分别将缓冲区模式设为行缓冲模式和10字符块缓冲模式,"abc"不能够填满缓冲区,此时暂停查看test.txt文件会发现内容为空;当我们使用hFlush函数手动刷新后,此时查看test.txt文件会发现内容已经出现在文件中。
提示:实际上,当用户使用
hClose函数时,hFlush函数将被自动调用,因此,即使我们不使用hFlush函数进行刷新,当我们关闭句柄后,内容仍然出现在了文件中
系统环境
System.Environment库中包含了系统环境相关的函数。这里简要介绍如何获取环境变量以及调用程序时传入的命令行参数。
环境变量
getEnv函数的类型为String -> IO String,该函数接受一个字符串,并将这个字符串所对应的环境包裹在IO monad中返回。例如在本机的环境中,查看PATH变量对应的环境。
Prelude> import System.Environment
Prelude> getEnv "PATH" >>= print
"/home/user/.vscode-server/cli/servers/Stable-b58957e67ee1e712cebf466b995adf4c5307b2bd/server/bin/remote-cli:/home/user/.opam/CP.2023.11.0~8.18~2023.11/bin:/home/user/.local/bin:/home/user/.cabal/bin:/home/user/.ghcup/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
命令行参数
getArgs的类型为IO [String],用于获取来自系统命令行中的参数。这里为了方便直接使用GHCi设置命令行参数,使用getArgs获取参数并计算参数的数目:
Prelude> :set args "1" "2" "3"
Prelude> :{
Prelude| main = do
Prelude| args <- getArgs
Prelude| print $ length args
Prelude|:}
Prelude> main
3
文件及目录操作
对于文件及目录进行操作是重要的IO操作之一,这些操作位于System.Directory中。
首先,createDirectory :: FilePath -> IO ()可以用于创建目录,与之相对的removeDirectory :: FilePath -> IO ()用于移除目录。然而removeDirectory的移除功能比较首先,其要求目录必须为空,不能有任何文件或子目录,当我们需要不加考虑删除目录时,应当使用removeDirectoryRecursive :: FilePath -> IO ()。
我们还可以对目录进行重命名或者移动。使用renameDirectory :: FilePath -> FilePath -> IO ()可以改变目录的名称;而使用setCurrentDirectory :: FilePath -> IO ()可以改变当前目录的路径。
除此之外,我们还需要对目录中的文件(夹)做一些操作。例如通过getDirectoryContents :: FilePath -> IO [FilePath]获取特定目录下的内容;findFile :: [FilePath] -> String -> IO (Maybe FilePath) 在指定路径下查找文件(不进行递归查找);renameFile :: FilePath -> FilePath -> IO ()对文件进行重命名;renameFile :: FilePath -> FilePath -> IO ()复制文件到另一个目录;removeFile :: FilePath -> IO ()对文件进行移除。
下面给出一个示例:
-- code'3.hs
directoryDemo :: IO ()
directoryDemo = do
createDirectory "demo"
writeFile "demo/test.txt" "content"
renameFile "demo/test.txt" "demo/new.txt"
renameDirectory "demo" "newdemo"
getLine -- 暂停查看目录
removeDirectoryRecursive "newdemo"
首先,函数创建了名为demo的文件夹,并向其中写入名为test.txt的文件,文件内容为"content",接着重命名文件名为new.txt,重命名目录为"newdemo";getLine函数中断程序执行,读者可以此时查看文件目录的状态,最后removeDirectoryRecursive函数将目录以及内部的全部内容删除。
有关更多的操作可以参考System.Directory
系统进程
下面介绍几个常用的系统进程相关的函数以及数据结构,读者可以自行查阅System.Process获取更多细节。
一个用于执行命令行命令的简单函数是callCommand,该函数的类型为String -> IO (),当我们使用该函数执行命令时,命令的回显将直接输出到终端上。
Prelude> import System.Process
Preldue> callCommand "lsb_release -a"
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.4 LTS
Release: 22.04
Codename: jammy
有时我们需要将命令与参数分开进行分析,此时可以使用callProess函数,该函数的类型为FilePath -> [String] -> IO ()。
Prelude> callProcess "lsb_release" ["-a"]
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.4 LTS
Release: 22.04
Codename: jammy
然而有某些情况下,我们希望回显存在字符串中而不是直接输出,因此可以使用readProcess,该函数的类型为FilePath -> [String] -> String -> IO String。前两个参数与callProcess中参数含义对应一致,第三个参数用来表示标准输入,即执行命令后为可能存在的标准输入提供内容。
Prelude> readProcess "lsb_release" ["-a"] "abc" >>= putStrLn
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.4 LTS
Release: 22.04
Codename: jammy
下面介绍CreateProcess类型,该类型是调用操作系统命令基础的类型,该类型及相关定义如下:
data CmdSpec = ShellCommand String
| RawCommand FilePath [String]
data StdStream = Inherit
| UseHandle Handle
| CreatePipe
data CreateProcess {
cmdspec :: CmdSpec,
cwd :: Maybe FilePath,
env :: Maybe [(String,String)],
std_in :: StdStream,
std_out :: StdStream,
std_err :: StdStream,
close_fds :: Bool,
create_group :: Bool,
delegate_ctlc :: Bool,
detach_console :: Bool,
create_new_console :: Bool,
new_session :: Bool,
child_group :: Maybe GroupID,
use_process_jobs :: Bool
} deriving (Show,Eq)
我们比较关心前六个参数,cmdspec表示命令,它要么是一条命令,此时参数与命令同为一个字符串,要么为原始命令,参数使用列表进行容纳。cwd表示运行命令所在的目录;env为执行命令添加了额外的环境变量;std_in、std_out和std_err表示处理标准输入输出和错误的方法,它们可以是从父继承过来、使用给定的句柄或者返回新的句柄。
一般情况下,我们只需要使用库中提供的函数即可,而无需手动配置这些参数。
shell函数的类型为String -> CreateProcess,可以用于生成带有ShellCommand模式的CreateProcess。
Prelude> shell "lsb_release -a"
CreateProcess {cmdspec = ShellCommand "lsb_release -a", cwd = Nothing, env = Nothing, std_in = Inherit, std_out = Inherit, std_err = Inherit, close_fds = False, create_group = False, delegate_ctlc = False, detach_console = False, create_new_console = False, new_session = False, child_group = Nothing, child_user = Nothing, use_process_jobs = False}
另一个类似的函数proc类型为FilePath -> [String] -> CreateProcess,用来生成带有RawCommand模式的CreateProcess。
Prelude> proc "lsb_release" ["-a"]
CreateProcess {cmdspec = RawCommand "lsb_release" ["-a"], cwd = Nothing, env = Nothing, std_in = Inherit, std_out = Inherit, std_err = Inherit, close_fds = False, create_group = False, delegate_ctlc = False, detach_console = False, create_new_console = False, new_session = False, child_group = Nothing, child_user = Nothing, use_process_jobs = False}
一旦我们创建了CreateProcess类型的值,就可以使用createProcess函数执行。createProcess的类型为CreateProcess -> IO (Maybe Handle, Maybe Handle, Maybe Handle,ProcessHandle),返回的IO monad中包含了三个句柄,分别为输入,标准输出和错误输出,第四个ProcessHandle表示进程句柄,可用于后续程序等待其终止。
Prelude> createProcess $ proc "lsb_release" ["-a"]
当然,根据需要我们也可以手动创建CreateProcess,例如指定输入输出的句柄,使其重定向到合适的数据流(如文件或者网络)。这里不再过多赘述,感兴趣的读者可以自行尝试。
有时,一个函数执行会消耗一定的时间,一般情况下我们可以在这段时间里处理其他的计算,然而,某些特殊的情况可能要求我们等待进程结束,此时可以使用waitForProcess :: ProcessHandle -> IO ()函数。
Prelude> createProcess (proc "sleep" ["3"]) >>= \(_,_,_,t) -> waitForProcess t >> print "wait for the process to be done"
"wait for the process to be done"
Prelude> createProcess (proc "sleep" ["3"]) >> print "without waiting for the process to be done"
"without waiting for the process to be done"
我们还可以使用getProcessExitCode :: ProcessHandle -> IO (Maybe ExitCode)获取进程执行的退出码。
Prelude> createProcess (proc "sleep" ["3"]) >>= \(_,_,_,t) -> waitForProcess t >> getProcessExitCode t
Just ExitSuccess
提示:
getProcessExitCode需要与waitForProcess联合使用,否则返回的永远都是Nothing
有时我们还希望直接结束某些耗时很长的进程:
Prelude> createProcess (proc "sleep" ["100"]) >>= \(_,_,_,t) -> terminateProcess t >> waitForProcess t >> getProcessExitCode t
Just (ExitFailure (-15))
使用terminateProcess :: ProcessHandle -> IO ()可以终止程序,上述示例中,可以看到进程被强制终止后,获得的退出码是异常退出。
不安全的IO
虽然我们希望将纯代码与不纯的代码进行隔离,但实际上Haskell仍然提供了一些后门操作System.IO.Unsafe。
| 函数 | 类型 |
|---|---|
| unsafePerformIO | IO a -> a |
| unsafeDupablePerformIO | IO a -> a |
| unsafeInterleaveIO | IO a -> IO a |
| unsafeFixIO | (a -> IO a) -> IO a |
读者应当注意,在使用这一系列操作时,副作用发生的相对顺序是不确定的,因此需要格外小心。
例如,我们考虑对于可变数据的操作,如下:
-- code'3.hs
import System.IO.Unsafe
val :: IORef Int
val = unsafePerformIO $ newIORef 0
val' :: IORef Int
val' = unsafePerformIO $ newIORef 0
unsafeDemo1 :: IO ()
unsafeDemo1 = do
x <- unsafeInterleaveIO $ readIORef val
y <- unsafeInterleaveIO $ writeIORef val 1 >> readIORef val
print x
print y
unsafeDemo2 :: IO ()
unsafeDemo2 = do
x <- unsafeInterleaveIO $ readIORef val'
y <- unsafeInterleaveIO $ writeIORef val' 1 >> readIORef val'
print y
print x
在GHCi中执行这两个函数:
Prelude> unsafeDemo1
0
1
Prelude> unsafeDemo2
1
1
unsafeDemo1函数先输出x,此时val中变量为0,因此读取的值也为0,接着输出更改后的y;unsafeDemo2函数先输出y,根据惰性求值,此时执行了对val'的修改,因此在后面输出x时,读取到的val'中的值为1。
实际编码中应当尽可能避免这些操作,有关更多的使用细节,读者可以自行参考System.IO.Unsafe。
[1] IO inside. (2024, April 22). HaskellWiki, . Retrieved 08:59, May 2, 2024 from https://wiki.haskell.org/index.php?title=IO_inside&oldid=66607.